YouTube has 100m+ daily active users who consume more than a billion hours’ worth of content every day. 100s of hours of videos are uploaded every second. At that scale, recommending personalized videos is a colossal task.
I’ve always wondered how YouTube is always able to come up with relevant recommendations that kept me hooked! I found a very interesting paper on Deep Neural networks for YouTube Recommendations. In this post, I will summarise the key ideas.
The Problem
To able to come up with relevant & personalized recommendations for every user is a problem because of:
- scale: billions of users, billions of videos.
- freshness: massive volume of videos are uploaded every day. It’s an explore-exploit trade-off between popular vs new content.
- noise: only sparse implicit user feedback is available for modeling.
In this paper, the authors demonstrate the usage of deep learning techniques for improving recommendations as opposed to matrix-factorization techniques used earlier.
Key Ideas
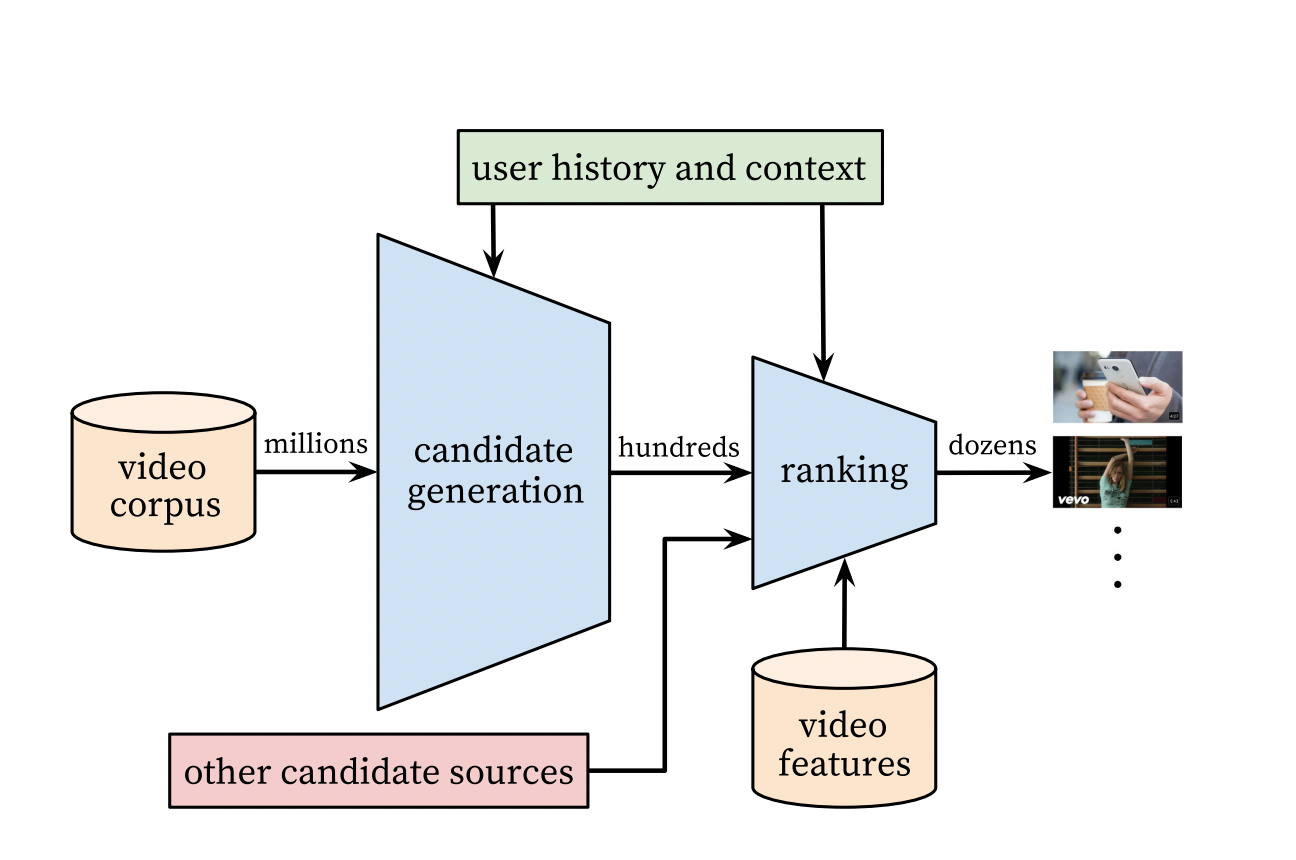
The problem of recommendations at scale is divided into 2 subproblems:
- Candidate Generation - selects a small subset from the overall corpus which might be relevant to the user.
- Ranking - ranks the candidate videos based on their relative importance.
For Candidate Generation, the objective is to predict the next video watch. User search/watch history, demographics, etc are used by a simple feed-forward network as embeddings which are jointly learned during the training.
For Ranking, the objective is to model an expected watch time. A score is assigned based on the expected watch time and videos are sorted accordingly.
Similar neural network architecture is used for both procedures.
Offline metrics like precision, recall, ranking loss, etc. are used during development. A/B test is used to determine the final effectiveness of the model. We’ve already explored the discrepancies between offline vs online evaluation in a different post.
Model Architecture
Candidate generation

** Problem Formulation:** Recommendation is formulated as an extreme multi-class classification P(w_t = i | U,C) = softmax(v_i . u) where, w_t = video v_i watched at time t U = user C = context v_i = dense video embeddings u = dense user embeddings
- The task of the deep neural network is to learn the embeddings u as a function of user history and context.
- user completing a video watch is a positive example.
- candidate sampling & importance weighting is used to sample negative examples.
Embeddings describing the watch history, user query, demographics, etc are fed to a simple feed-forward neural network having a final softmax layer to learn the class probabilities.
- watch history: dense vector representation of watched video is learned from a sequence of video-ids (just like word2vec).
- user query: n-gram representations
- demographics: geographic region, device, age, etc. are used as numerical/categorical features
The embeddings are jointly learned while training the model via gradient descent back-propagation.
Age of the video is used to model the time-dependent nature of popular videos. Otherwise, the good old popular videos are going to be selected most of the times, isn’t it?
What’s interesting is that a lot of features were “engineered” as opposed to the promise of deep learning to reduce it.
Training data & label:
- There’s an inherent sequence of video consumption. Hence, using random held-out data will be cheating since future information will leak into the training process. The model will overfit! Think about time-series forecasting. A random train-test split won’t work since the future data is not available in production during serving time.
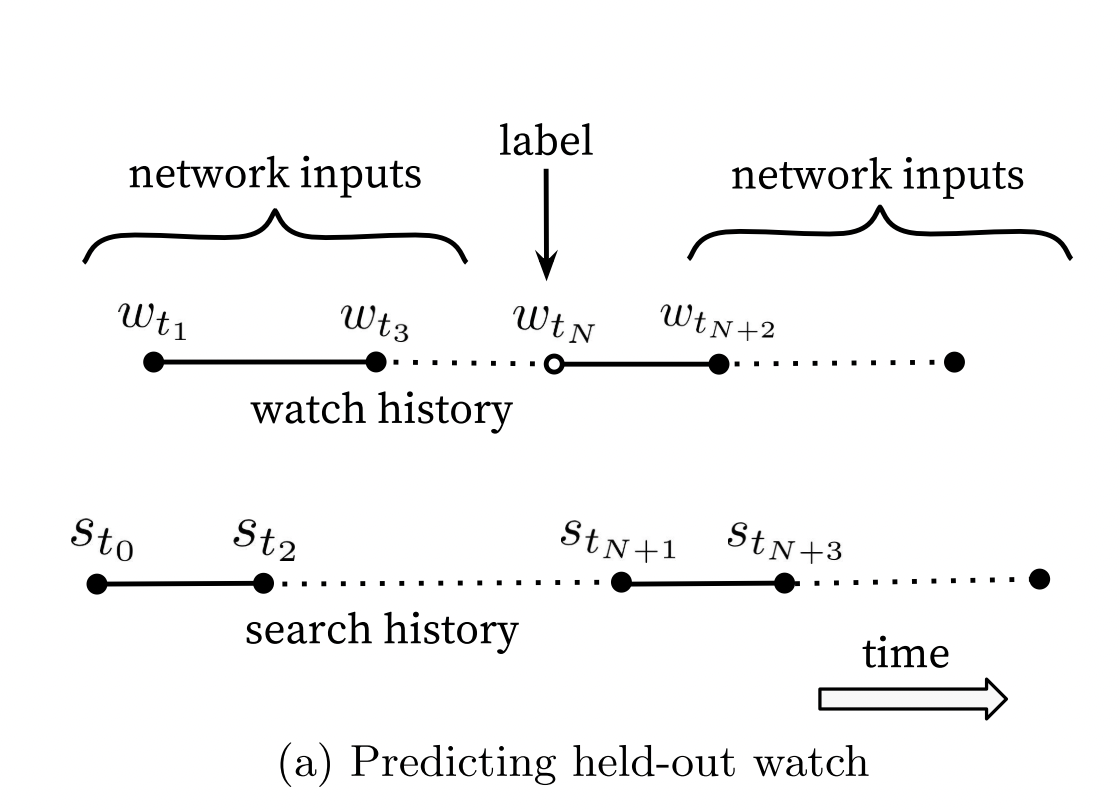
- The authors propose a model of predicting user’s next watch instead of a randomly held-out watch. This makes sense, as we consume videos in a sequence. For example, if you’re watching a series with several episodes, recommending a random episode from that series doesn’t make sense.
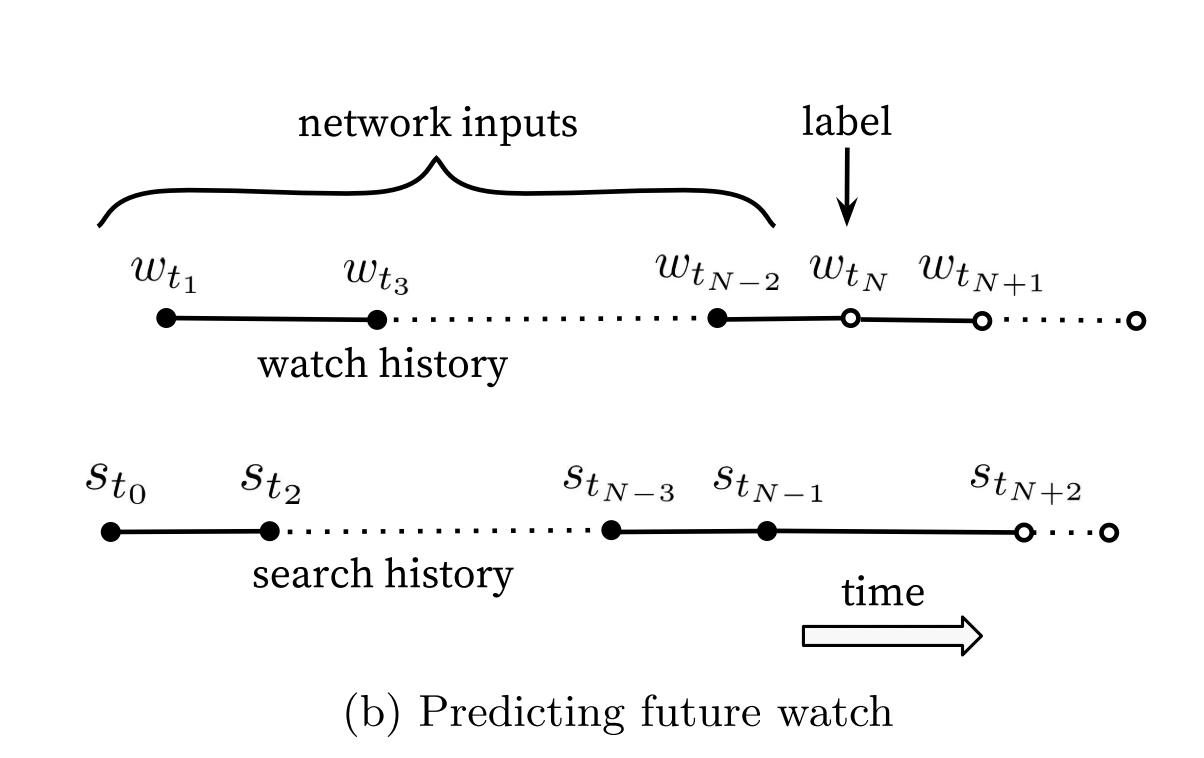
- There’s an inherent sequence of video consumption. Hence, using random held-out data will be cheating since future information will leak into the training process. The model will overfit! Think about time-series forecasting. A random train-test split won’t work since the future data is not available in production during serving time.
Serving:
- To score millions of videos in latency of tens of milliseconds, a nearest neighbor-based search algorithm is used. Exact probability values of softmax() are not required. Hence, a dot product of user and video embeddings could be used to figure out the propensity score of a user u for a particular video v_i. A nearest neighbor search algorithm could be used to figure out the top K candidate videos based on the score.
Ranking
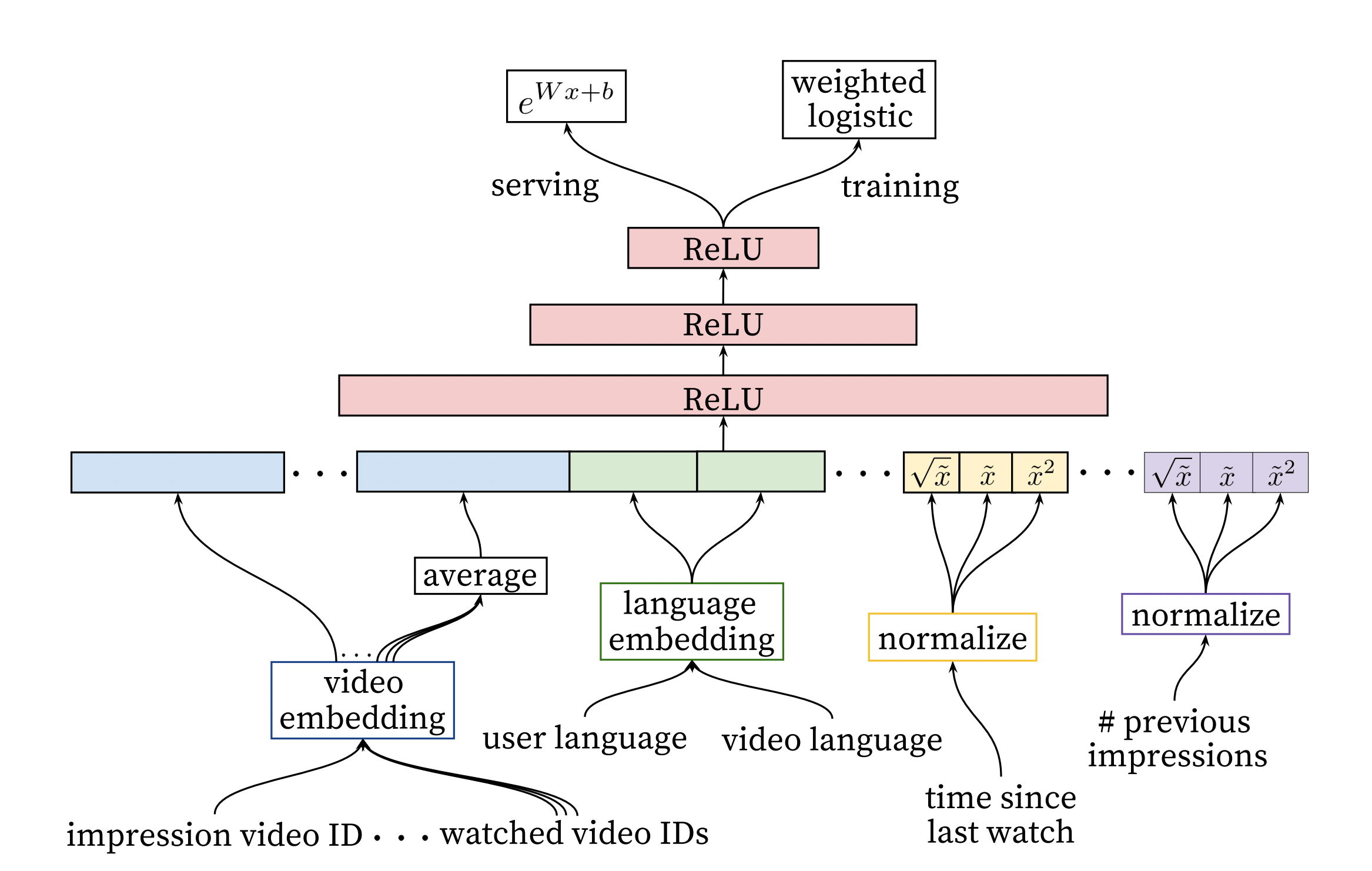
- Candidate generation selects a few hundred out of millions of videos. The ranking procedure could make use of more video features as well as user’s interactions with it in order to figure out an order of recommendation.
- The model architecture is similar to the candidate generation procedure. We assign a score to the videos using weighted logistic regression.
- The objective to optimize is a function of expected watch time per impression.
- Why not click-through rate? Well, that would promote clickbait videos instead of quality content. Watch time is a better signal that captures engagement.
- Modeling Expected Watch Time
- Objective: Predict expected watch time for a given video.
- Model: Weighted Logistic Regression, since the class distributions are imbalanced.
- Positive example: the video was watched.
- Negative example: the video was not clicked.
- What are the weights in “weighted” logistic regression?
- Positive examples are weighted by the watch time.
- Negative examples are given a weight of 1.
- Loss: cross-entropy